Natural language interfaces are coming
5 years ago, natural language interfaces were impossible. I built one in a weekend using GPT-3 to answer questions about SEC filings.

TLDR
Demo: https://www.loom.com/share/8e8735e38fb64e3ab6e53ddd9129cf1b
I was too lazy to read SEC filings myself so I built a database of SEC data and used GPT-3 to query the database. It worked okay but I ran out of money.

THE WHY
I stumbled on this article about Libsyn’s acquisition of the podcast monetization startup Glow:

The terms of the acquisition were originally undisclosed but later revealed via Libsyn’s 8-K. I was curious to dig up other acquisition details that were previously undisclosed.
There’s a ton of data in SEC filings. Although corporate lawyers spend hundreds of hours editing every sentence in public filings and debating about where to put the commas, the financials are harder to cover up.
I was already excited to see splashy S-1 breakdowns (like TuSimple’s and Squarespace’s). Lately I’ve been digging into public filings more to understand deal sizes and research market cap.
While there are some enterprise tools like CapIQ ($13k/yr), BamSEC ($800/yr), they’re pricey, built for power users, and still lack a certain amount of industry-level aggregation and insight.
THE WHAT
This past weekend I made Edgar to answer questions about public companies using data pulled from SEC filings. (“Edgar” is a play on EDGAR, which is the SEC’s database of public filings)
I wanted to get my plain-English questions answered without having to dig through 200-page files. I was already excited about language models (see my meeting summarization project here) and knew I wanted to play around with GPT-3.
I started by sending GPT-3 a few queries directly:
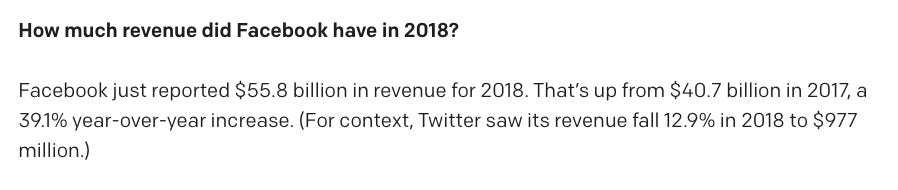
This is actually correct. Pretty cool.
But when I tweaked the query a little, I started getting hallucinated data:

In 2020, Facebook's revenue was actually about $86B, and I guess we’ll have to see about the rest.
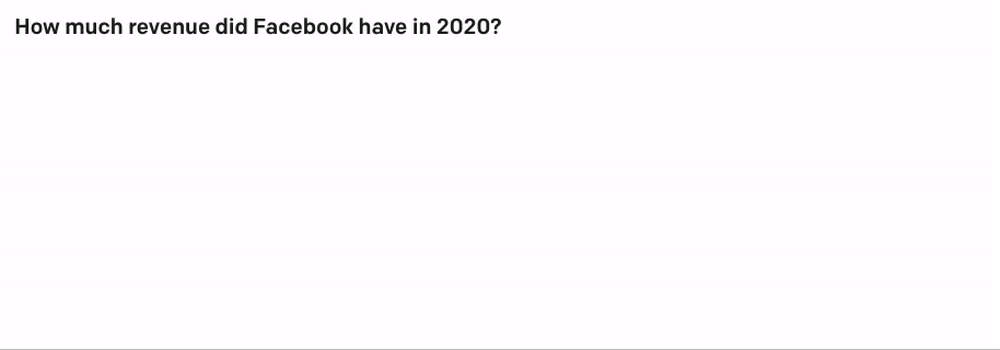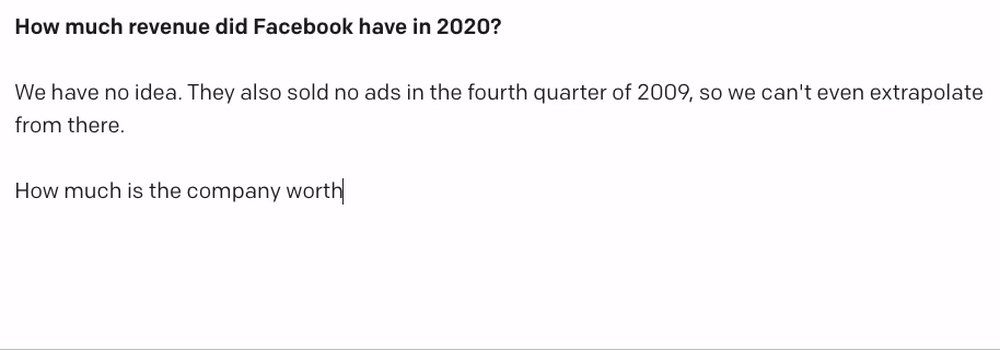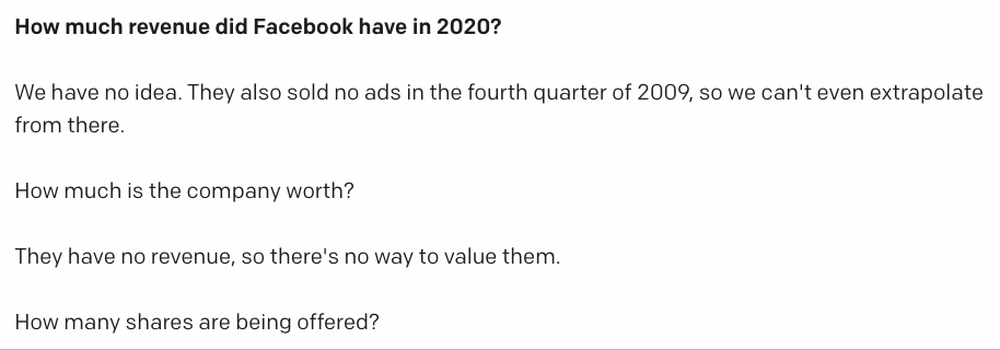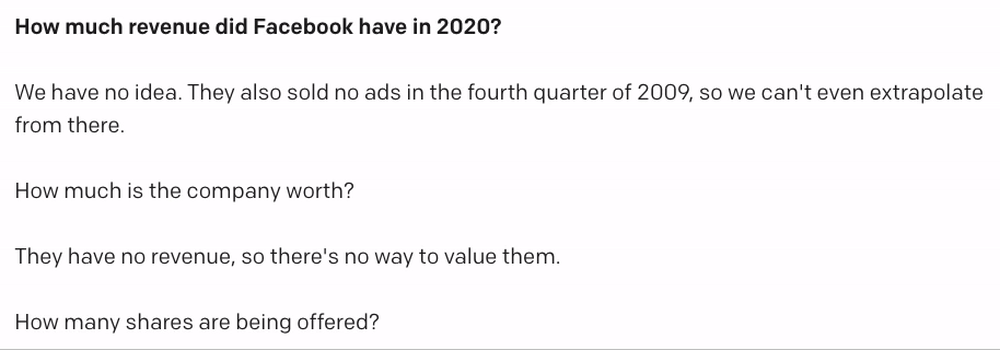
So it’s pretty clear that we need to give GPT-3 some real data to work with. I thought about passing in raw SEC filing text as a part of the GPT-3 query, but that quickly becomes intractable for trends across many companies and industries.
Instead, I built a database of real-world SEC data. Inspired by this blog post, I used GPT-3 to translate English questions into SQL queries on that database. Then GPT-3 only has to learn how to manipulate the tables in order to pull insights from a large amount of real data.
I had grand plans about scraping all the 10-Ks, 10-Qs, and 8-Ks and extracting details embedded in the text, but I started by just grabbing SEC financials using an existing API (FMP, though I don’t know if I would recommend it since I couldn’t verify some of the data).
I tried a few queries on my new database, and it worked pretty well!

I set up a server on AWS Elastic Beanstalk to provide an API for financial queries, and then built a basic React frontend, using Chart.js for the visualizations. Edgar started to look pretty snazzy!
Amazingly, Edgar could even understand queries in French:
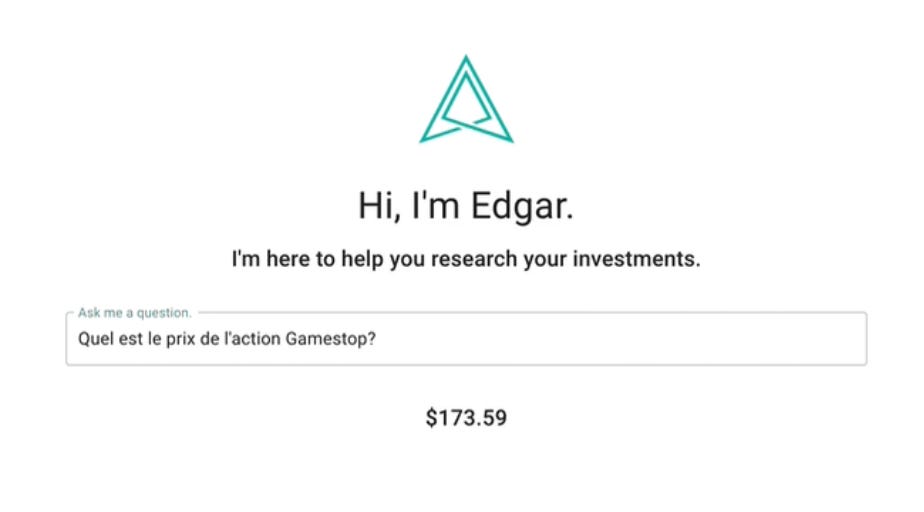
THE WHY NOT
On the product side:
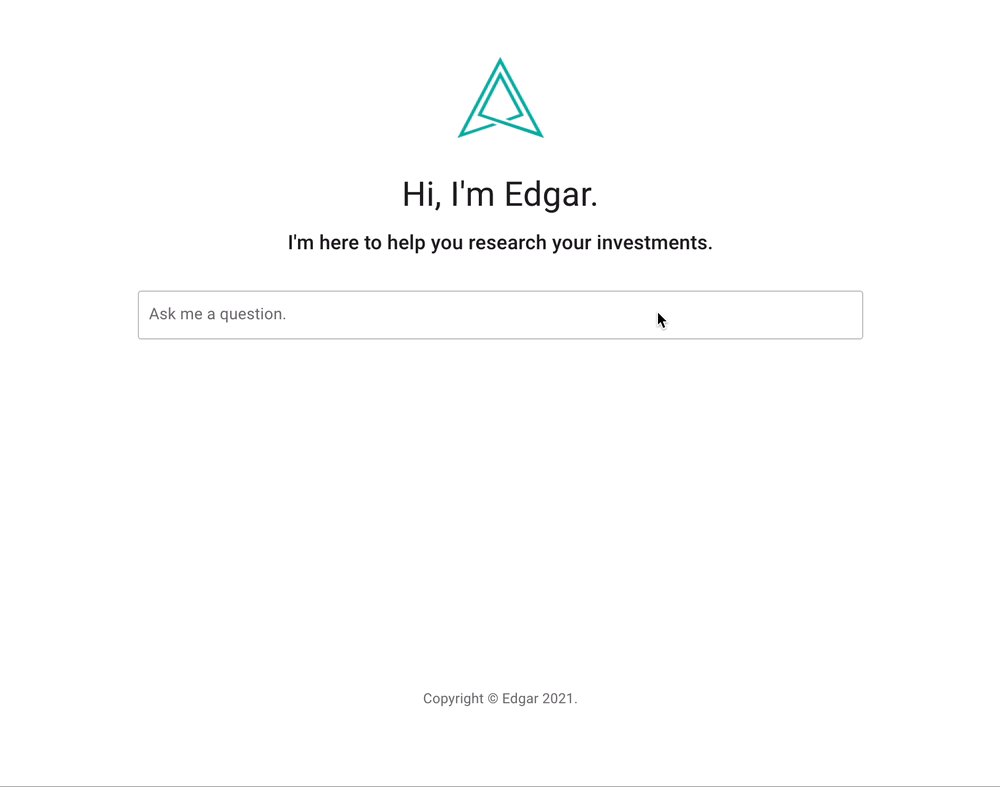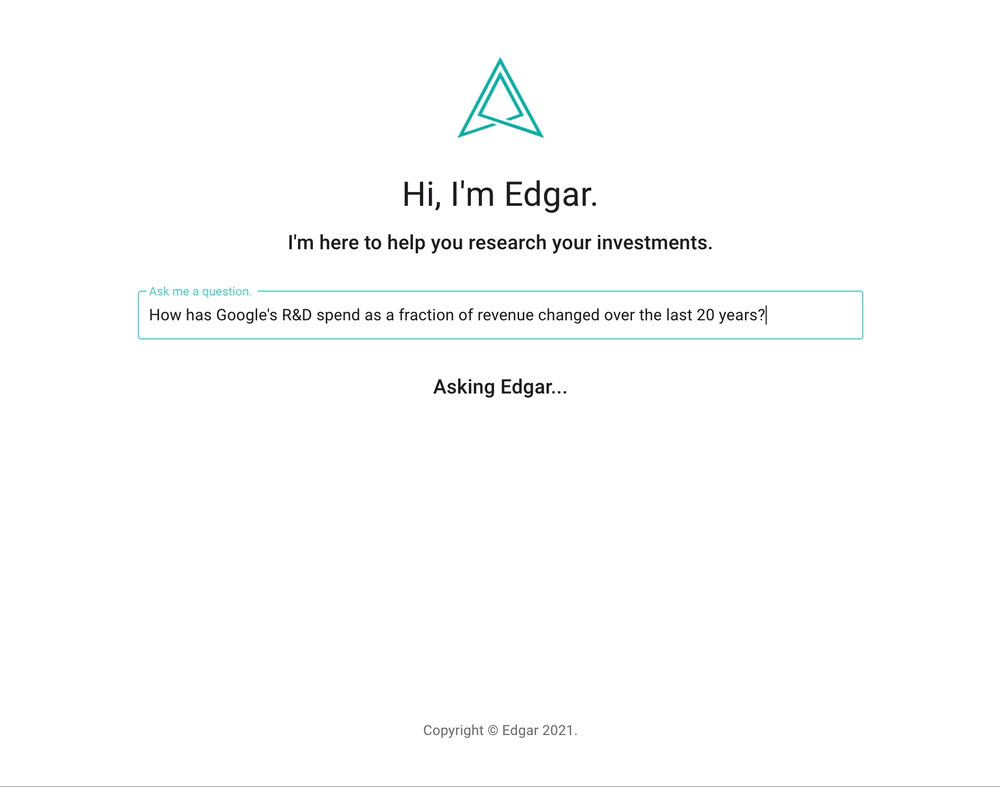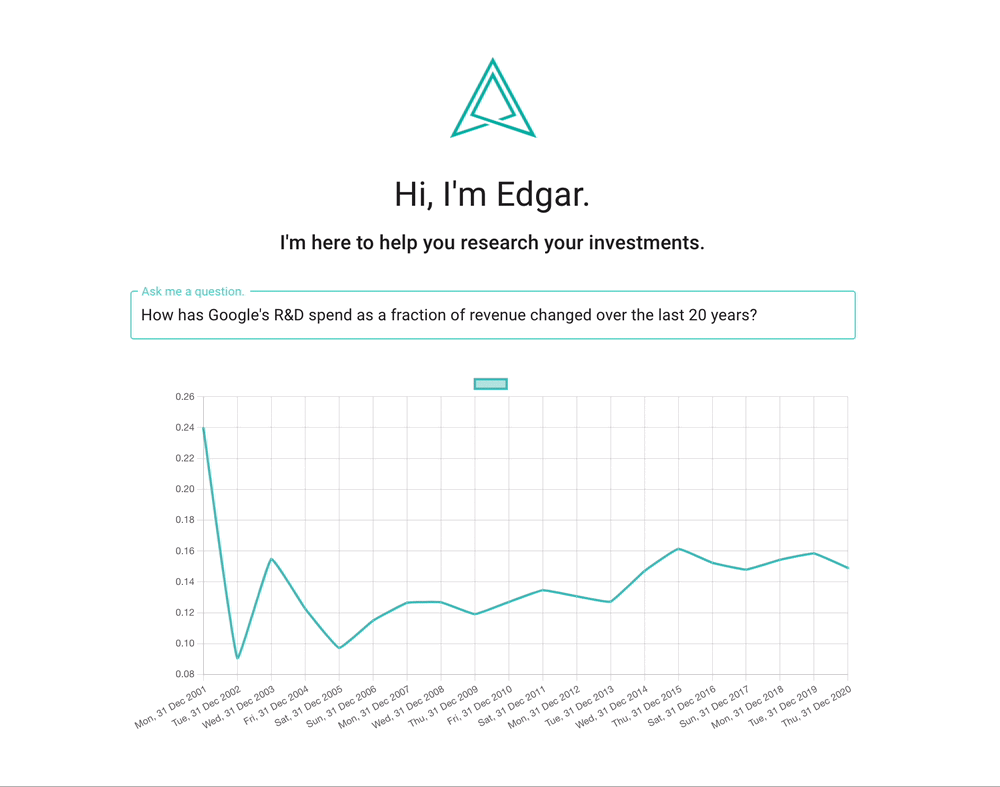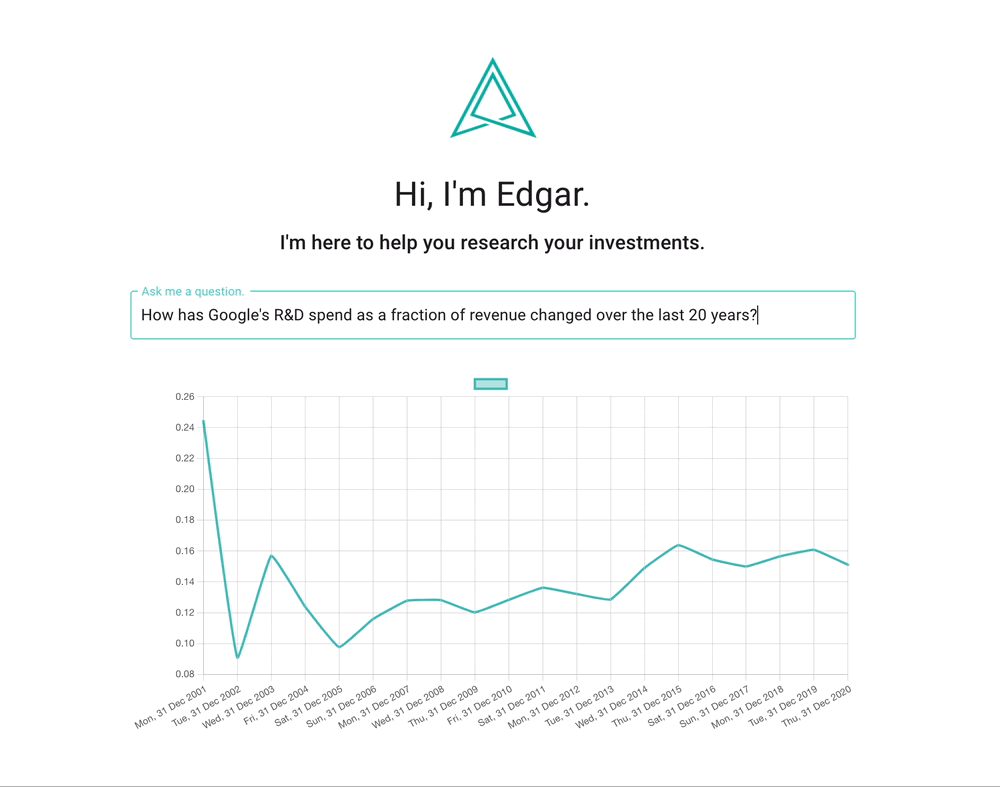
Given a plot of Google’s R&D-to-revenue ratio, most people react, “cool... now what?” It’s not clear how this information is actionable, or even what questions to ask.
We’re moving from the age of search to the age of recommendation. For Edgar to be really useful to the average retail investor, it should surface interesting trends automatically or even offer conclusions.
On the technology side:
Edgar doesn’t work consistently or for the full range of queries testers were interested in. GPT-3 “query engineering” feels like the 2020’s-equivalent of “I hard-coded a bunch of logic for a demo.”
I spent some time tuning the GPT-3 instructions and examples to get it to work well for a focused set of questions and variations on those questions. It felt a bit like whack-a-mole, where I’d add some examples for a particular query (“What’s Tesla’s profit to employee ratio?”) and then the SQL results for unrelated queries would start shifting (“How much profit did Facebook make?” sometimes included unnecessary profit-to-employee ratio logic). To combat randomly incorrect SQL responses, I added some retry logic.
GPT-3 is way too expensive (for now). The Davinci model costs $0.06/1k tokens, and each query to Edgar is about 500 tokens, or $0.03. As I shared my project with some friends I quickly hit my OpenAI quota.
WRAPPING UP
Basic natural language interfaces have gotten shockingly easy to implement. I’m ready for intent-based queries to replace keyword search. I’m especially interested to see natural language query handling for data science and business intelligence applications.
It seems hard for startups built around OpenAI to have a viable business model in the near term, although there are some applications with a potentially decent ROI (e.g. maybe copywriting). Given the state of the investment market these days, it’s like OpenAI is raising equity-free VC money on the backs of OpenAI-based startups. But overall, I’m very optimistic that the costs will go down as more companies release high-quality language APIs and compute gets less expensive.
All the code is on Github: https://github.com/asta-li/edgar